大模型知识汇总-截止到2025年8月
(1)基础
transformer
- 输入: 接受input id序列,转变为token的语义embedding序列,每个token再加上位置embedding的到最终的embedding序列。
- encoders:多个相同结构的encoder堆叠组成,每个encoder的数据流程均为:self-attention –> add&norm(残差连接) –> Feed Forward Network –> add&norm(残差连接)。 最终转变为另一种含义的embedding序列(同输入维度)。抽出最后一层的k和v向量,输送decoder。
- decoders:
- 多个相同结构的decoder堆叠组长,每个decoder的数据流程均为:Mask self-attention –> encoder-decoder-attention –> add&norm(残差连接) –> Feed Forward Network –> add&norm(残差连接).
- 生成过程:首先基于一个固定起始special-token,通过decoders转变为embedding,取最后一个token对应的embedding通过liner层转变为词表维度的一维向量,经过softmax作为概率,取概率最大的index对应的词进行输出。再将这个词加到刚开始的special-token后面,进行循环生成。
- Mask self-attention(与encoder区别之一)是为了防止未来位置的token信息影响到当前位置token的生成,具体实现就是通过一个下三角矩阵作为掩码矩阵,其他位置为-∞,使得最终结果softmax为0。
- encoder-decoder-attention(与encoder区别之一)的k和v来自encoders最后一层
self-attention
- QKV向量:是由输入token的embedding向量经过三个QKV矩阵,得到的低纬度向量,QKV矩阵通常都为N*N的维度,N为输入序列token长度,因此序列越长QKV矩阵越大。
- 除以根号d的意义是,使QK之后的分布方差跟d无关,softmax不会呈现一种随d增加而突出陡峭的状态,训练更加稳定
- flash-attention:将QKV分成多个小块,每次只计算一小块的attention输出,再进行累加得到完整的attention结果,本质上是时间换空间,增加计算量,但能大幅降低显存,因为不需要保存一份完整的N*N矩阵。
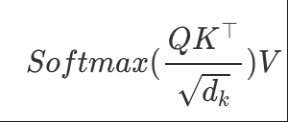
Norm
Norm的使用场景是:训练数据分布差异较大,模型在训练过程中不仅要根据训练目标学习,还要学习训练样本的差异,导致模型训练不稳定,难以收敛。 而通过Norm就能让数据分布变得简单,模型能够更加专注学习训练目标。而不同的Norm方式就是就是应对数据在不同维度上的分布差异
- layer-norm:对一个样本的不同维度特征进行归一化,通常这里的不同维度是具有重叠相似性,比如序列,才有归一化的意义,因此常用语NLP领域。transformer中使用的是layerNorm,但实现来说是对每个token的embedding进行归一化,因此其实是instance norm
- batch-norm:对batch内样本的同一组特征进行归一化,通常用于CV领域
更多详细可以看这个:《Transformer似懂非懂的Norm方法》
模型应用
- encoder模型:通常用于推荐领域
- decoder模型:通常用于问答生成领域,此时decoder需要删除encoder-decoder-attention层
- encoder-decoder模型:通常用于翻译领域
(2)LLM
SFT
- loss:交叉熵损失(cross-entropy),对每个token*p(token)
- 微调方式:
- 全参数微调:全部模型参数都参与训练,显存需要加载全部参数,资源消耗最大,理论上性能最高,但可能导致灾难性遗忘,需要大量的训练数据。
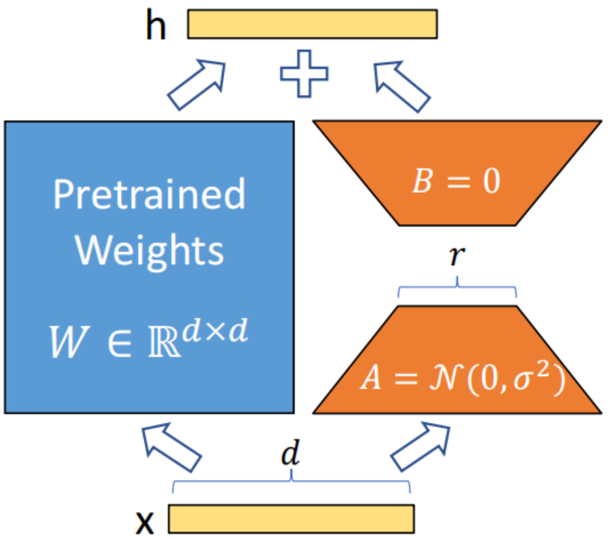
- Lora:在原来模型的FFN层旁边增加一个旁路,通过两个可训练小矩阵进行低秩分解(先降维后升维),将结果接到FFN层的输出中,来模拟参数更新。训练参数非常少(通常不到原模型1%),训练速度快,稳定性高。
- QLora:在Lora的基础上,将原模型以4bit低精度方式储存,进一步降低显存消耗,但推理时需要反量化回16bit,因此训练时间会比Lora长一些。
- 训练加速
- deepspeed:通过将优化器的状态、梯度、甚至权重参数在分布式环境中进行分割,降低显存消耗/提升显存利用率,用通信开销时间换取显存降低,适用于训练长序列/超大模型。
- megatron:通过数据并行(dp)、模型并行(pp)和张量并行(tp)和硬件加速,能够极致提升计算效率,解决单GPU显存无法放入一个完整模型的问题。
- 推理加速
- vLLM:通过pageAttention和内存共享优化,优化KV cache缓存来提升推理速度。详细了解:《vLLM核心技术PagedAttention原理》
- 降低推理精度:Fp16,还可以进一步使用量化int8压缩,依赖英伟达显卡
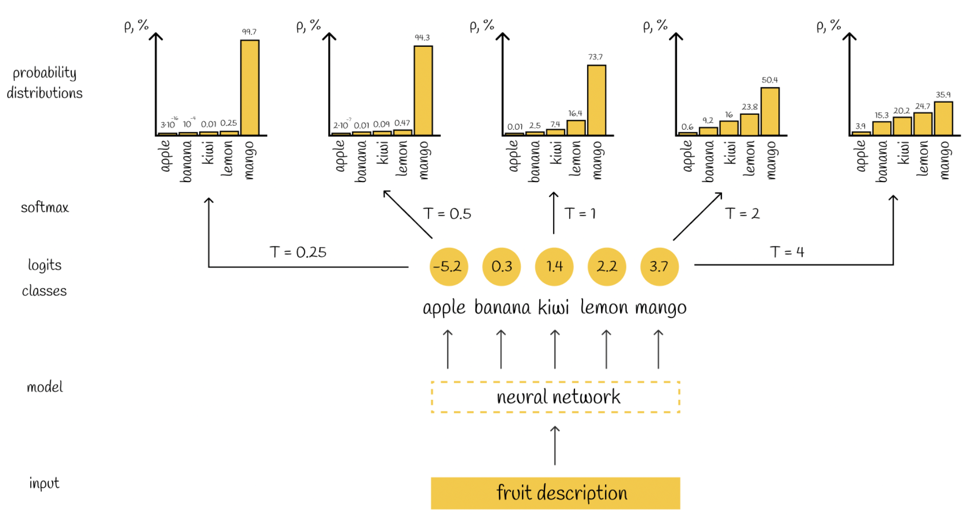
- LLM生成随机性控制
- temperature:影响softmax函数,softmax函数中的指数会除以这个t,t越大,则softmax之后的结果更加均衡,大小差异更小,softmax之后小值的概率变大了,从而随机性更高了。
- 引入t前后的softmax函数:
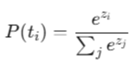 vs
vs 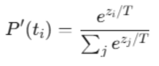
- 引入t前后的softmax函数:
- top-k:每一步生成只考虑概率最高的k个token,再按照其概率进行采样,k越大随机性越高。
- top-p:每一步生成将token按照概率从大到小排序,选择概率累计超过p的token,再按照其概率进行采样,同样p越大随机性越高 更多详细可以看这个:《关于LLM的TOP-p、top_K、temperature》
- temperature:影响softmax函数,softmax函数中的指数会除以这个t,t越大,则softmax之后的结果更加均衡,大小差异更小,softmax之后小值的概率变大了,从而随机性更高了。
RLHF(PPO)
- Actor模型:正在训练的LLM,基于prompt生成优化答案
- Reference模型:pretrain+sft之后的模型,同样基于prompt生成一个参考答案,用于约束Actor模型的生成答案分布不能偏离太多(KL散度)。
- Critic模型:对Actor模型生成的优化答案给出预估得分(predict label)
- Reward Model:对Actor模型生成的优化答案给出真实得分(true label)
- PPO训练过程:先利用偏好数据训练一个reward model,才能开始LLM训练;这是一种强化学习方式,采样一批prompt,生成答案,计算预估得分和真实得分,进而得到优势(梯度),叠加Reference模型的KL散度约束,对actor模型参数进行更新。
- 缺点:多次交互训练,较为复杂
DPO
- 训练过程:不属于强化学习,对比PPO,砍掉了复杂的critic模型和reward model,将偏好数据直接应用到模型训练目标中,利用BT模型的思想,最大化chosen样本生成概率减去rejected样本生成概率,使模型尽可能生成chosen样本的偏好。也会有KL散度约束。
- 问题:实际训练过程中,训练目标只是扩大chosen样本和rejected样本的差距,但并不保证rejected样本损失的概率能转移到chosen样本的生成概率,甚至造成输出结果完全错误。因此通常还会增加一个对chosen样本的sft-loss
GRPO
- 训练过程:属于强化学习,对比PPO,砍掉了critic模型,通过对一个prompt的多次采样答案得到多个reward,并取平均得到平均reward,用答案reward减去平均reward来代表每个答案的优势,同时将KL散度直接加到损失函数中进行优化。
- 优点:训练更加稳定,显存和计算资源都有所下降
MOE模型
- 本质:代替attention之后FFN层的一种新网络结构,该结构能够只激活部分参数,就能计算得到下一层embedding,在不降低参数量的情况,能大幅降低计算量,从而提升训练和推理速度。
- 网络结构:
- 专家网络(Expert Network):多个FFN层,代表多个专家,所有专家都接收相同的输入,产生不同的输出。
- 门控网络(Gating NetWork):接收与专家相同的输入,产出不同专家的重要程度权重
- 选择器(Selector):根据专家权重选择专家的策略,可以选择topN个专家
- 核心需解决问题:
- 负载均衡:由于选择器是根据专家重要程度进行选择的,可能存在大部分网络都由头部几个专家网络激活,导致少数专家通信繁忙并拥堵,而其他专家则训练不充分。
- deepseek解决方案:
- 划分更细粒度的专家,并隔离出共享专家
- 专家级的负载loss和设备级的负载loss(V1和V2版本):针对loss进行修改,使模型输出如果覆盖更多专家或更多设备时,loss是更低的
- 无辅助损失的负载均衡(V3版本):不再用loss进行负载均衡(会增加与优化目标无关的计算量),而是通过bias来调节不同专家的激活概率
(3)LLM4Rec
字节的HLLM
- 先训练一个基于item的LLM,获取item embedding。
- 再用item embedding去训练基于user的LLM,预测下一个感兴趣的item embedding,通过生成式推荐loss和判别式推荐loss共同训练。
小红书的noteLLM
- 用prompt的方式,组装一个item笔记信息,然后输出一个代表压缩信息的special token。
- 训练目标有三个,一个是协同共现item的相似性loss,一个标签的sft loss,一个是类别的sft loss,共通去训练训练生成的token embedding,进行i2i召回。
快手的oneRec
- 第一步,通过一个多模态表征模型将视频映射为很多组向量,再通过Qformer将多组向量压缩为4组向量,再用RQ-kmeans将向量映射为语义ID。
- 第二步,将用户信息和各种行为序列输入到LLM模型,进行生成式推荐任务的训练。
- 第三步,用生成结果上线曝光,拿到点击数据进行一个类似精排模型的训练,作为一个reward model,再结合其他格式reward等模型,对LLM进行grpo的RL训练。
- 优化后的GRPO:有个提前裁剪操作防止梯度爆炸,使训练更加稳定,同时砍掉了KL散度的loss,让模型一直日更。
快手oneSug
- 第一步,将前缀和query进行embedding化,然后用前缀相关的query对前缀的embedding进行表征增强,感觉类似一种修正,再通过RQ-vae生成语义id,最后就基于语义id进行检索召回topk。
- 第二步,将用户信息和前缀输入LLM,进行query的推荐召回,sft任务
- 第三步,DPO训练进行用户偏好对齐,dpo做了一定的优化:
- 将pair-wise改为list-wise,充分利用偏好序列数据。
- 引入了一个行为权重,对不同的行为序列有不用权重reward,让dpo不仅能够学习预估值的排序,还能拟合预估值本身。
关于LLM4Rec中遇到的问题和思考
由于LLM的排序能力是比较弱的,经过SFT训练LLM4Rec模型一般只能做召回,通过后续线上精排模型来筛选topN进行透出。
然后在RL阶段加入精排模型或者用户反馈点击,进行DPO或者GRPO训练,强化模型生成更加符合点击分布或精排分布的推荐,这个时候会发现一种奇怪的现象,经过RL之后的模型在hitrate@1指标会有所提升,但在hitrate@all指标没有提升甚至下降,因为RL会让模型的推荐范围收窄,让模型精准给出特定推荐,从而失去发散性探索能力,尤其是进行bean_search搜索多次结果的时候,RL模型生成的推荐范围相比SFT模型更加窄。
但LLM4Rec模型在线依旧需要以来精排模型,只能做一路召回,而召回的本质趋近发散性探索,应该尽可能返回用户可能感兴趣的候选集,再由精确筛选透出,与我们RL阶段的目标存在一定矛盾,导致实际上效果更差了。 与最近的几篇关于SFT和RL模型在探索和精确指标上的对比报告有点相似,所以LLM4Rec在性能提升方向很重要的问题就是解决发散性和精确性的权衡:
- 可以在提升发散性的时候稳定精确性:比如在SFT阶段,对同一个样本多次采样,通过reward model筛选高质量样本,类似拒绝采样。
- 在提升精确性的时候稳定发散性:比如在RL阶段,在reward model中加入发散性指标(参考《使用pass@k作为RL reward》),需要精心的设计,或者引入一些噪声样本、高熵样本、高探索性样本,或者最简单的跟sft交替训练
- ext:论文还指出,优先学习低PPL(perplexity,困惑度)样本能够提升RL性能,让模型集中在把握度更高的样本里面学习会是更优的学习策略,这跟拒绝采样有点相似。
(4)其他LLM应用
RAG
- 检索阶段:对用输入进行关键词提取、实体识别等,然后基于比如向量检索的方式,从预处理好的文档库中检索出相关的材料。
- 增强阶段:对检索出来的材料进行去重、截断、排序等预处理。
- 生成阶段:将处理好的检索信息,跟原问题一起输入到大模型中进行答案生成。
Agent
- 基本概念:将原本LLM无法解决或者无法很好解决的任务,通过任务拆解、推理执行、工具调用,与环境多次交互产出更好的结果
- 任务拆解:LLM对用户指令进行目标识别,关键知识提取等
- 推理执行:对任务进行拆解,推理出执行的子任务,给予chain-of-thought或reason-act等方式
- 工具调用:调用各种api,或者其他模型,或者RAG的方法,得到子任务的结果
- 执行反馈:综合子任务结果得到最终结果,并进行自我纠错
多模态LLM
- 模型结构:
- 模态编码器:将多模态数据编码成向量空间特征,常用CNN的resNET、Transformer结构的ViT等;
- 输入投影层:将上面得到的向量特征映射到LLM输入特征空间的适配层,通常较为简单,如MLP、Cross-Attention;
- LLM主干网络:经过预训练的LLM网络,串联多个模块一起SFT,使LLM能够识别多模态输入的token或向量;
- 输出投影层:将LLM生成数据映射到其他模态的特征,同样为简单的MLP或Tiny Transformer;
- 模态生成器:基于上面特征生成其他模态的输出。如图像的Stable Diffusion,视频的Zeroscope,音频的AudioLDM;
AE、VAE、VQ-VAE、RQ-Kmeans
通常用于对各种维度特征(比如图像、音频、id序列)进行编码,输出另一种更加具象化、或更简短、或更有聚集性的特征。多模态相关的模型经常使用。
- AE(Auto-Encoder):
- 目的:对输出特征(图片、序列)做压缩,生成一个特征代表原始图片的所有信息。
- 实现方式:自编码器是一种无监督神经网络,通常由一个编码器将高维度输入数据特征编码到低维度embedding,再用解码器将embedding重建回原始表现形式,最小化输入特征与重建特征的差异,让中间生成embedding能够包含输入特征所有信息。
- 存在问题:AE生成的低维度embedding所在编码空间是离散的,在这个编码空间中随机取一个离散点(embedding)进行解码器重建,解码器是无法理解的(泛化能力差),这种特性在特征提取任务中是无所谓的,但在生成任务里面是完全不可用的
- VAE:变分自编码器
- 目的:使编码器的输出embedding空间是一个连续分布,从中随机采样一个点,都能通过解码器输出合理的原始特征(比如图片)
- 实现方式:在编码器输出的结果m之上,叠加一个高斯分布噪声项n,实现对编码器输出结果的随机偏移r=m+n,重构损失函数的训练会使r的分布趋近于标准正态分布,从而实现在这个embedding空间的任意采样点,都能重构出一个合理的原始特征。
- 区别:编码器在隐空间为每一个输入特征产生是一个概率分布(而不仅仅是一个embedding),具体为这个高斯分布的均值和方差参数,然后解码器从这个分布中随机采样一个点,重构特征
- 详细了解:《AE/VAE/CVAE/VQ-VAE》,《从自编码器(AE)到变分自编码器(VAE)再到条件变分自编码器(CVAE)》
- VQ-VAE:向量量化
- 本质:属于AE,而不是VAE,因此是做特征压缩用的,但和AE的区别是,生成的中间特征是离散特征ids,而不是一个连续特征embedding,并且ids中每个id会对应一个embedding,所以实际上表示的信息更多。
- 实现方式:输入特征通过编码器得到embedding特征,构建一个编码表,在这个编码表里面用knn检索最相近的k个向量,k个id即为输出目标——离散特征id。
- 巧妙的设计:因为从embedding到离散特征id的映射过程是非连续的(knn),在BP中无法回传梯度,这里使用了stop-gradient的方法,直接忽略非连续映射带来的梯度,在BP中依旧使用embedding特征计算回传梯度。
- 详细了解:《VQ-VAE的简明介绍:量子化自编码器》
- RQ-VAE:残差量化
- RQ-kmeans:
- 本质:属于AE,也是做特征压缩表示,生成离散的中间特征ids
- 实现方式:对全局向量进行kmeans聚类,得到n个聚类中心,编号,即为第一个码本,然后每个向量减去聚类中心向量(残差)得到新向量,循环聚类编码,得到第N个码本,最终原向量可以表示为每个码本的编号:<3,6,…>
- 优势:码本不需要训练更新,直接计算可得
模型蒸馏
- 目的:有一个待压缩的大模型和一个小模型,让小模型在大模型的监督下进行优化,学习大模型的概率分布,从而将大模型的知识蒸馏到小模型
- 实现方式:
- 黑盒知识蒸馏:准备一批prompt,让大模型生成结果,构造出prompt-response数据直接sft小模型
- 特点:实现简单,LLM独有的,更加主流,需要精心设计的prompt,对生成样本进行扩充、纠正、过滤等处理
- 白盒知识蒸馏:直接对齐小模型和大模型的输出概率分布或隐含层概率分布,通过KL散度约束使两个概率分布趋同。
- 黑盒知识蒸馏:准备一批prompt,让大模型生成结果,构造出prompt-response数据直接sft小模型
